SAP Basis & Virtualization Services
Hi guys,
I am offering Remote SAP Basis Support and Service to your company. No matter your company have dedicated SAP Basis or not, we can help you. Your company could hire me as Remote SAP Basis.
I also have virtualization support on VMware, Proxmox VE, Linux, Oracle, and DB2. Usually, I support my client via TeamViewer connection.
You can contact me through
Email : devratt@yahoo.com
Phone/SMS/WA/Telegram : +62-81336451502
How to check db2 recovery process
[db2inst1@emadwh3 ~]$ db2 list utilities show detail
ID = 1
Type = CRASH RECOVERY
Database Name = DWH
Member Number = 0
Description = Crash Recovery
Start Time = 04/27/2023 07:12:46.168546
State = Executing
Invocation Type = User
Progress Monitoring:
Estimated Percentage Complete = 40
Phase Number [Current] = 1
Description = Forward
Total Work = 814690500000 bytes
Completed Work = 647811883486 bytes
Start Time = 04/27/2023 07:12:46.168580
Phase Number = 2
Description = Backward
Total Work = 814690500000 bytes
Completed Work = 0 bytes
Start Time = Not Started
[db2inst1@emadwh3 ~]$ db2pd -recovery -db DWH
Database Member 0 — Database DWH — Active — Up 0 days 03:59:53 — Date 2023-04-27-11.12.20.724981
Recovery:
Recovery Status 9000000F40088005
Current Log S1005378.LOG
Current LSN 0000048434716D53
Current LRI 000000000000000100000007F468DBB50000048434716D53
Current LSO 2018963846634260
Job Type CRASH RECOVERY
Job ID 1
Job Start Time (1682554366) Thu Apr 27 07:12:46 2023
Job Description Crash Recovery
Invoker Type User
Total Phases 2
Current Phase 1
Progress:
Address PhaseNum Description StartTime CompletedWork TotalWork
0x000000024D45B568 1 Forward Thu Apr 27 07:12:46 648827679888 bytes 814690500000 bytes
0x000000024D45B6F0 2 Backward NotStarted 0 bytes 814690500000 bytes
[db2inst1@emadwh3 ~]$
Unknown webmethod: WaitforServiceStarted
Problem
maqtst01:tstadm 4> startsap
Checking TST Database
Database is running——————————————-
Starting Startup Agent sapstartsrvUnknown webmethod: WaitforServiceStarted
Startup of Instance Service failed
See /home/tstadm/startsap_SCS01.log for details
Solutions
– Execute this command sapcpe on /sapmnt/[SID]/exe.
Format:
sapcpe -nr pf=profile
Ex:sapcpe -nr 00 pf=/usr/sap/TST/SYS/profile/START_SCS01_maqtst01
SAP maintenance certificate crack spam/saint version 7.0
After a day of exploration, I found that the methods given on the Internet are all unavailable due to the SPAM upgrade, and finally found a way to crack the maintenance certificate. The summary is as follows: The key to cracking the maintenance certificate is the modification of the program: OCS_CHECK_MAINTENANCE_CERT. , The program cannot be modified. After exploration, I have found a way to modify the program:
1. Create an SAP account (you can copy DDIC permissions), and modify the user group to Developer:
2. Find the program: LSKEYF00 , Remove the edit lock permission;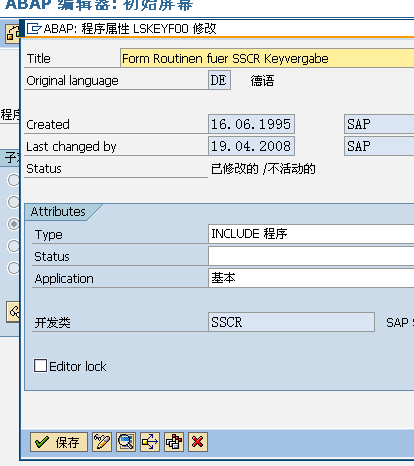
3. Modify OCS_CHECK_MAINTENANCE_CERT, and modify the sy-subrc value to 0 in the figure below. After the compilation is successful, you are done.
4. No prompt appears after running rain.
Source : https://blog.titanwolf.in/a?ID=00200-4824cc3b-2d8d-489a-bca2-a5bdc8baf678
SAP Solution Manager Key Generator (linux version)
The following bash script should produce installation key for SAP Solution Manager (SOLMAN) basing on three input values: SID, SN and HOSTNAME.
The script is based on popular VB script available here: http://kohanov.com/tmp/sap_keys.vbs
Feel free to use/modify/redistribute the script for both private and commercial use.
#!/bin/bash# SAP Solution Manager Installation Key Generator# by: redloff (IRCnet: #+kwa)# based on: http://kohanov.com/tmp/sap_keys.vbs# license: free for personal and commercial useif [ $# -ne 3 ]; then echo "use: $0 " exit 1fiif [ ${#1} -ne 3 ]; then echo "SID has to consist of exactly 3 characters" exit 2fiif [ ${#2} -ne 2 ]; then echo "SN has to consist of exactly 2 characters" exit 2fifunction ascii { echo -n $1 | od -d | sed -n "s/^.* //gp"; }SIDSN=`echo $1$2 | tr [a-z] [A-Z]`SERV=`echo $3 | tr [a-z] [A-Z]`for i in `seq 0 $((${#SIDSN}-1))`; do SIDSNhex[$i]=`ascii ${SIDSN:${i}:1}`done##echo "SIDSNhex: ${SIDSNhex[*]}"for i in `seq 0 $((${#SERV}-1))`; do SERVhex[$i]=`ascii ${SERV:${i}:1}`donefor i in `seq ${#SERV} 14`; do SERVhex[$i]=0done##echo "SERVhex: ${SERVhex[*]}"if [ ${#SERV} -gt 0 -a ${#SERV} -lt 5 ]; then for i in `seq ${#SERV} 4`; do SERVhex[$i]=32 #ascii space char done## echo "SERV between 0 a 5"fiif [ ${#SERV} -gt 5 -a ${#SERV} -lt 10 ]; then for i in `seq ${#SERV} 9`; do SERVhex[$i]=32 #ascii space char done## echo "SERV between 5 a 10"fiif [ ${#SERV} -gt 10 -a ${#SERV} -lt 15 ]; then for i in `seq ${#SERV} 14`; do SERVhex[$i]=32 #ascii space char done## echo "SERV between 10 a 15"fi##echo "SERVhex: ${SERVhex[*]}"for i in `seq 0 4`; do reshex[$i]=`echo $(((((0^${SIDSNhex[$i]})^${SERVhex[$i]})^${SERVhex[$(($i+5))]})^${SERVhex[$(($i+10))]}))`done##echo "reshex: ${reshex[*]}"reshex[0]=`echo $((${reshex[0]}^84^0))`reshex[1]=`echo $((${reshex[1]}^131^11))`reshex[2]=`echo $((${reshex[2]}^194^46))`reshex[3]=`echo $((${reshex[3]}^52^105))`reshex[4]=`echo $((${reshex[4]}^119^188))`##echo "reshex: ${reshex[*]}"hexstr=(0 1 2 3 4 5 6 7 8 9 A B C D E F)for i in `seq 0 4`; do hihex=`echo $((${reshex[$i]}/16))` lohex=`echo $((${reshex[$i]}%16))` resstr=${resstr}${hexstr[$hihex]}${hexstr[$lohex]} doneecho "Installation key: $resstr"To use the code, just paste it into a file (ex: solmankg.sh)
Set execution rights (chmod 755 solmankg.sh)
Execute the script with three arguments: SID, SN, HOSTNAME (ex: ./solmankg.sh AA1 00 FLUFFY)
Un-officially SAP OSDB Migration Project done !!
Another project have been completed by me this year.
Since the sister company (formerly I maintain) moved to hyperconverged Nutanix and used Acropolis as its hypervisor, there is a SAP R / 3 4.7 ext 200 system running on HP rx4640 machine with HPUX 11.23 OS and Oracle 9.2 database server that must be migrated to a Nutanix machine . HP rx4640 machine is not extended maintenance support. While the system, SAP R / 3 4.7 ext 200 is also not supported by SAP both SAP instance and database server.
Target using Linux OS SLES 11 SP4 and DB2 database server 9.7 FP 5.
Broadly speaking the migration process is :
– Export existing data in SAP R / 3 4.7 ext 200 on HPUX source machine
– Install DB2 9.7 database server on target Linux
– Install Central Instance on Linux target
– Install Database instance in Linux target by selecting System Copy and export result (process no.1) as imported data.
The export process runs smoothly. Problems begin to emerge during process no.4 of them:
The process of database load had stopped because the file system is full sapdata. Solution: extend the sapdata partition and the file system
The database load process was stopped again because the file system is a full archive log. Solution: extend the partition and add the number of LOGARCHIVE second files.
After the import process is complete, there are still more problems that arise, the SAP kernel 6.40 used does not recognize the linux 3.0 kernel (used SLES 11 SP 4) and DB2 9.7 database. The solution is download the latest version of SAP kernel 6.40 EX2 patch (version 414).
Project un-official SAP OSDB migration done by un-certified Base like me
How to compare SAP user roles
I have a few question on how to compare different object from 2 SAP users so that I can see the different between them. I’ve searched on google and found useful SAP standard report “RSUSR050”.
From this report, we can see object levels different from 2 SAP users. Its nice report though.
Here are the screenshot.

Enter both SAP user which is want to be compared and execute.

